
Accomplishments
- Fine Matching Speed Reduced By 90%
Bonus
- Improved Pose Graph Accuracy
- Normal Estimation
- Depth Confidence Voting
- Fused Point Cloud
As the quantity and capacity of datasets grows, so does the time it takes to test them all. To test under so many conditions can be cumbersome, and even moreso when one of the steps is taking over 15 minutes to complete. This week I set out with the main goal of increasing productivity by improving the fine matching speed as best as I can. I was able to reduce this by over 90%, while also having enough time to further improve the pose graph, and begin implementing the following meshing step.
Fine Matching Speed Reduced By 90%
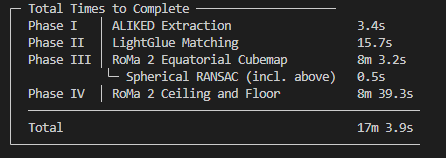
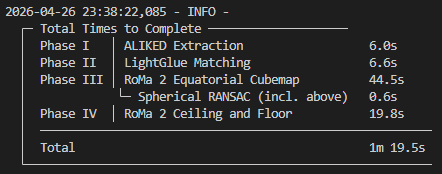
By far the longest step in the pipeline is currently the fine matching process. Multiple factors exist which make this process so time consuming. We discussed many of these in Week 14. We solved the N-Choose-2 comparison problem by using the lightning fast LightGlue as an early coarse refinement step, narrowing down what might need to be compared. We also ran a spherical ransac operation (at the time, also reduced by 90% speed) on the matches to further confirm them. And then we progressed into a time intensive fine-matching stage with RoMa V2.
RoMa V2 provides further confidence that the images are actually matches, which are the strongest, and where in the image they match. It is very time intensive, and through a variety of steps we were able to reduce this time by 90% as well. We were able to do this through a variety of steps. First we were able to introduce threading. Some tasks needed to be handled by the CPU, and some by the GPU. Previously, the GPU was stopping while the CPU completed its tasks, leaving time on the table. Now the GPU performs all its tasks, handing off the information as it goes for the CPU to pickup and work in tandem. We also receive a huge time improvement from using the fuse-local-corr, a feature provided by RoMa’s developer that was made specifically to provide faster time on certain hardware.
We also added a change to compile the libraries to work with our specific hardware. This runs on startup, and takes around 2 minutes, but once performed, each subsequent run performs much faster! And lastly, we tweaked the way we distributed our matches across tiles to be more efficient.
Through these changes, RoMa 2’s time was brought down significantly. It went from taking over 17 minutes, to just over 80 seconds. This greatly improves our ability to test matches, latter improvements, while also increasing efficiency as datasets continue to grow.
Bonus: Improved Pose Graph Accuracy

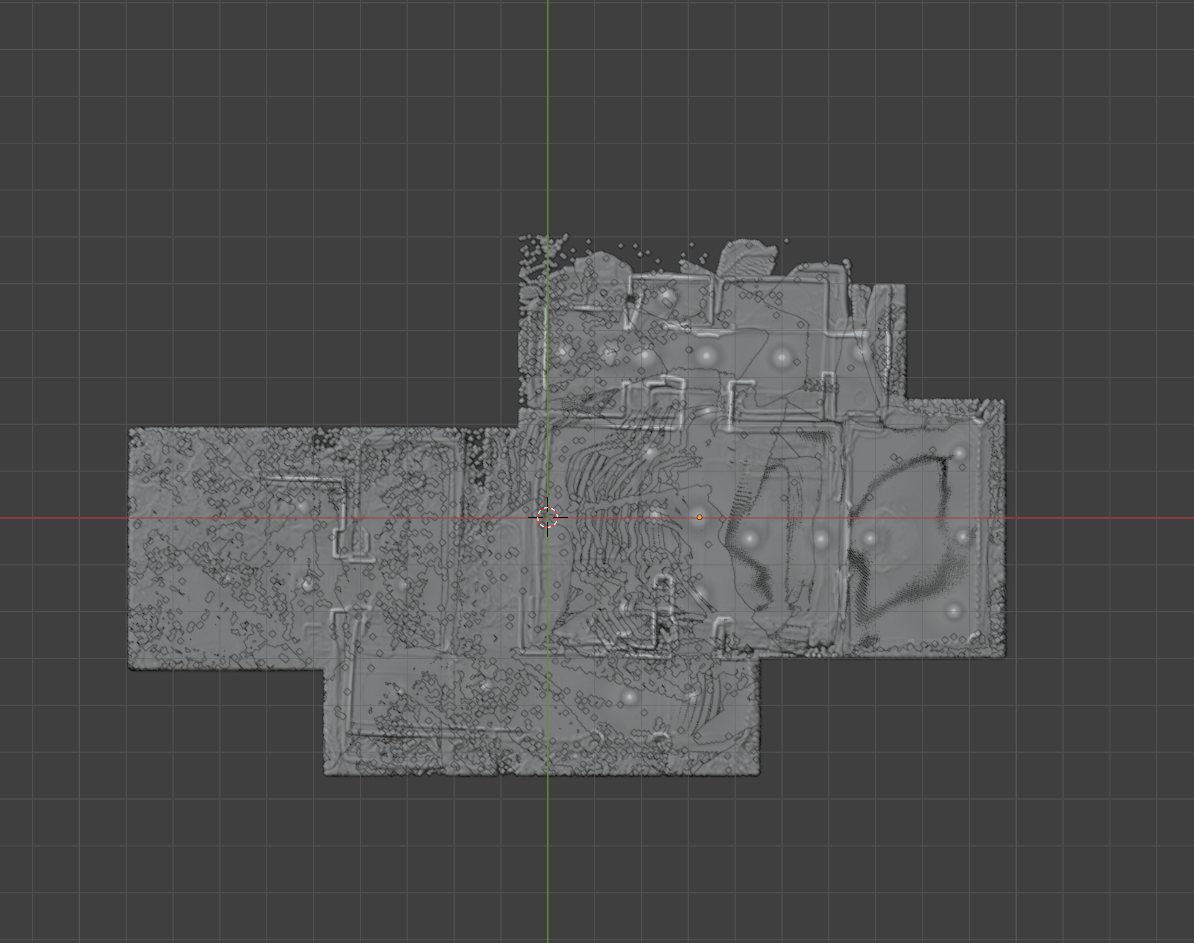

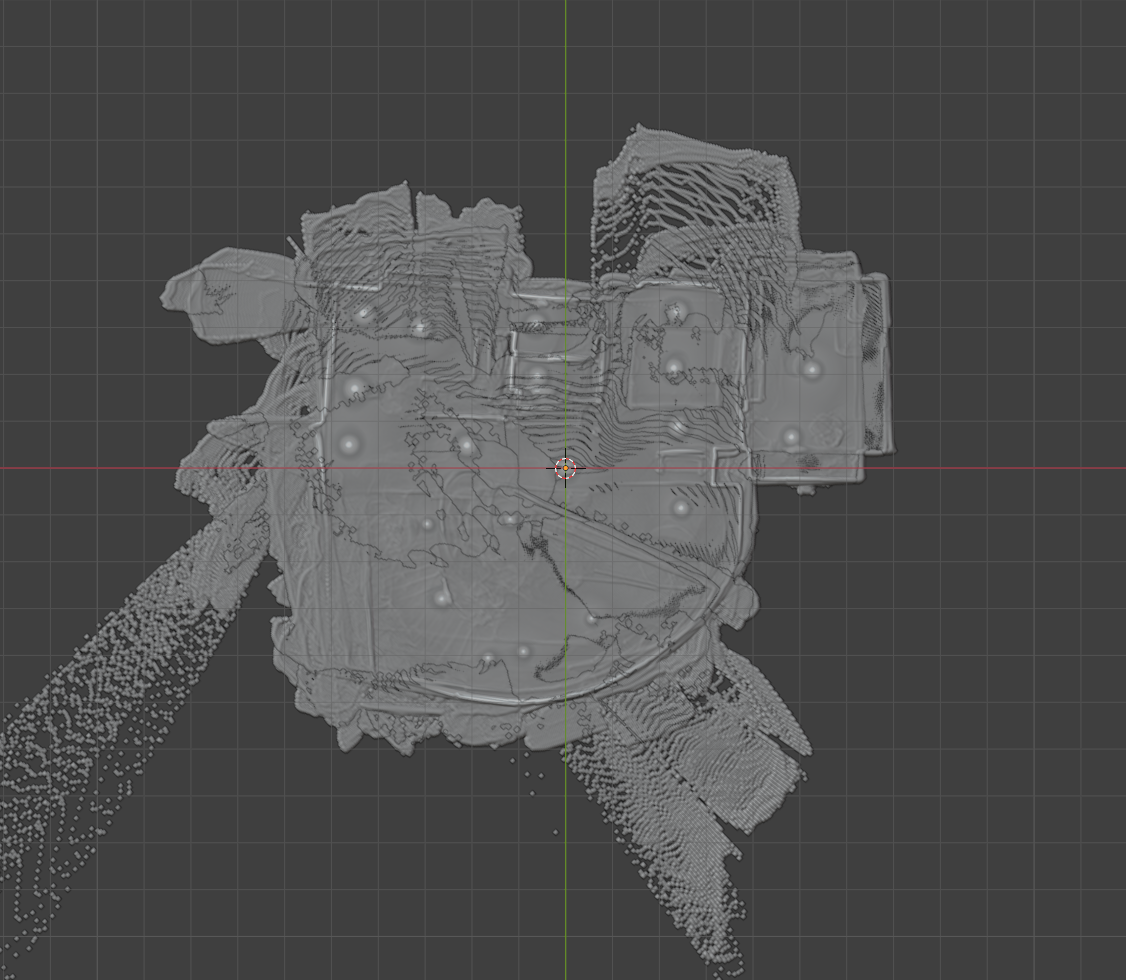
Last week we tested 4 datasets and only half of them appeared very accurate. After reviewing the results I was able to identify a variety of improvements to be performed. One being opening match rescue. In some cases openings from the coarse matching have very low confidence and do not enter into the second round of matching. Now, regardless of confidence, if a certain fraction of the matching points appear within an opening we promote it to the following round. This is purely additive, so that this low confidence candidate does not take the place of a higher confidence value in the limited number of positions being picked for round two. Instead, the number of items for round two expands. Now our doorways are preserved through coarse matching to be confirmed in fine matching.
I also made some improvements to the distance calculation formula. Some matches had still been winning competitions even if more points were further. To combat this I added a maximum limit to the point depth. This means that extremely far points should not contribute to the confidence of the matched images. Skyscrapers, or fixtures beyond a long corridor, should not outweigh the features nearby, even if there are many more of them.
Bonus: Normal Estimation

With so many kinds of estimation (Depth, Pose Graph, Keypoint, etc) its nice to finally hear about a “Normal” one. To those unfamiliar with 3D graphics the concept of ‘normals’ may sound anything but. Normals are a thing, every point in a 3D scene has them. You can imagine them as a little toothpick sticking out of the point in the direction it most ‘flatly’ faces. For example, the floor beneath your feat, those normals point straight up. The ceiling, those point straight down. Your glass of water, each degree points out in each direction. To reconstruct a 3D scene every point in our point clouds must have them too.
Thankfully this is a common problem, and calculations exist to help in solving for the normals based on a depthmap and the camera’s position. Now the pipeline has accurate normals for the generated 3D depthmaps to be used in later steps.
Bonus: Depth Confidence Voting


So far we have our matches, our pose graph, and our depth maps. When posed, most of the point clouds overlap. There are overlapping walls. There are false positives, where edges stretch out or small plants or items end up in different positions. Far away data like high ceilings or distant rooms may be inconsistent over few point clouds. There are even so many loose points that you can’t even fly through the aligned space to admire it visually! What can we do to reduce the quantity of false positive data across our depthmaps? We can vote.
Since each of the camera’s knows where they are in relation to eachother, and each has it’s 2D depthmap available with the distance to each point, we can use these to construct a 3D matrix and compare across images what should be where. This way, if 3 cameras next to the bed all say the bed is in the center of the room, and the 1 camera from the hallway says it is against the wall, the hallway’s input is removed, and the three cameras in the room confirm the bed’s location.
This process happens for every pixel in each depthmap. To keep this calculation reasonable we use something called voxels. Voxels are like Minecraft, every space is taken up by a block. We determine what cameras see the same area, and cast rays out from them. We look at the same block of space in 3D and ask the cameras “what do you see here”. If cameras A, B, and C all say “Pillow” then that’s probably where the bed’s pillow is, even if camera D says “empty”.
But what if you only have camera A and Camera D, who wins then? Distance and angle are two known attributes that can help us. For each camera, our distance is accurate to about 2.5 meters in range. So if A is 1m away, and D is 4m away, A has a much stronger vote and determines that the pillow exists. And what if they are at a similar distance, but D thinks there is nothing there? Perhaps D is looking at a sharp angle. Earlier angle was determined by the normals, and sharp angles are harder to verify. So even if A and D are in the same place, if A has a more head-on view, and D has a much sharper view, A’s vote will win.
These confidence votes compound and collect across multiple neighbors determined by the pose graph and where the camera can raycast to before it hits a wall. To debug this process I have begun drawing visual confidence maps to better illustrate why certain features are appearing, and others may be missing.
Bonus: Fused Point Cloud








With cameras posed, normals collected, and point confidence determined, I was able to build the first iteration of fused point cloud generation. The voted confidence is used to determine what points from the depthmap should actually be displayed in 3D. This cuts out a lot of floating noise and hallucinated walls. Thanks to every step up to this point, we were able to generate a mesh that accurately outlines each room in the scene.
Improvements are definitely required for better accuracy. As some doorways are still blocked, walls are incomplete, and overlapping spaces cause strange cuts and jagged edges. Improvements to confidence voting, as well as using other information available to use, should be useful in order to improve this new result going forward.
Summary
Speed and accuracy are often considered two of the most important features in a process. This week I was able to improve both of them. Through a variety of actions our fine matching stage was able to be reduced by 90%. And on top of that, pose graphs were able to be improved alongside the first iteration of a new meshing feature. It’s incredibly to go from week 12’s two-camera proof of concept mesh to these multi-room meshes with well aligned pose graphs. It’s incredible to see the power of this process and I cant wait to see what more it can do.
