
Accomplishments
- Depthmap improvements
- Removed Sky
- Flattened Glass
- Metric Depth Estimation
- Alignment improvements
- Distributed Sample of Matched Points
- Restricted Alignment Vectors (Yaw only, no scale)
- Doorway Recovery
- Sharp Edge Recovery
- Depthmap improvements
Each step of the process relies on the accuracy of the data prepared by each of the previous steps. To most accurately determine the position of each camera, we must confirm that the matches are accurate in 3D space, and that they fit together just like they would in the real world. This week, we were able to greatly improve our alignment accuracy by using available data to refine the depthmaps, and identify low-accuracy depth matches and recover with an alternative alignment process.
Depthmap Improvements
Sky Removal

This simple step removes all points related to the sky for a given depthmap. This reduces the visual clutter when building the process while also simplifying the process of cleaning up the point clouds down the line. The empty void of the atmosphere has no accurate depth, therefore has no value for these stages of the process.
Flattened Glass



Clear glass in architecture is often used to see beyond a point. When looking at glass windows or walls in 3D it’s common to expect to see the solid structure, rather than sporadic holes in the space. I added a procedure to flatten the points identified as glass output by the depthmapping tool.
The depthmapping tool itself did fairly well at identifying tinted glass as a flat object. I noticed that in some cases the glass would be ignored ad the depth would be generated through the glass. This inconsistency lead to surprising holes in the wall. Glass also can cause a slight refraction, or bend in the light going through it. This caused the holes to further corrupt the depth estimation with inaccurate refracted expectations.
Flattening the glass worked well and even improved the overall shape of the room in some cases. This improves the accuracy of the individual point cloud and should reduce the time spent during some future cleanup phase.
Metric Depth Estimation






In Week 12’s report I discussed the tradeoffs between two tools used for depth estimation. One offered metric accuracy (most) of the time and had warped structure, the other had accurate structure but the metric accuracy varied widely. I moved forward with the second tool for its improved geometric accuracy, believing that someday metric accuracy could be applied with a scale adjustment. Today was that day.
While ideating ways to improve my image alignments I reflected on what intrinsic data is available from the included photos. Upon this reflection I realized two important values I had taken for granted. The camera’s height and being level with the horizon (more on that in a following section). During shooting the camera remains at about eye level on a stand. This stand maintains roughly the same height throughout the capture process. Because the depthmaps tend to be accurate in the floor immediately below the camera, we can scale this distance to align with the value of the camera’s stand. This drastically improved the consistency across depthmaps.
While the metric depth estimation drastically improves the process, some challenges still persist. The current stand in use is adjustable. That means over time, and from small changes and gravity the camera may accumulate centimeters of change in height. Also, slight angles like those of a hill or slope may lead to improper ground estimation and a larger inaccuracy to scale. Both of these can be solved with real-world adjustments to the stand and capture process. A fixed height stand with a tilt-able base could keep the camera level and over the pole while fixing its height to the ground with great accuracy.
Another challenge this scale does not yet solve is that of incorrect depth over slight changes in elevation. For example, in the related images there exists a ground truth elevation change between the hard-wood floor and the kitchen area. The depthmaps for both the kitchen and the hardwood floor ignored this change and hallucinated a level area. Because of this, the floor for the kitchen appears confused, with two estimates, one from each camera. This may be something able to be rectified during a point cloud cleanup phase, though if unchecked has potential to accumulate scale drift over time.
The metric depth estimation greatly improves the accuracy of depthmaps while drastically reducing the opportunity and magnitude of scale drift. All identified challenges have potential solutions to be later implemented.
Alignment Improvements
Distributed Matches





This week began with only the highest confidence matches being used to align two point clouds. Sometimes the highest confidence matches may group themselves in small areas. This makes alignment difficult. Think of it like a door. With hinges it has 1 or 2 matches on the same vertical line. A door still connects at those points whether its open or closed. Now think of a dead bolt, or a lock. When the door must be locked AND on its hinges, it only has one position.
Instead of taking only the highest confidence matches, I decided to use a distribution of high confidence matches. In most cases this spread the matches across a wider area. While the matches may be less perfect, the overall structure will be more perfect. For example we can look at the secondary entrance and the shoe closet. The sparse, highest confidence, keypoints cluster in a few small straight lines. Then we look at the dense matching. Here the points cluster along a much wider field of view, almost the whole horizon.
By transitioning from sparse, highest confidence, keypoints to a distributed selection of high confidence keypoints I greatly improved the degree of accuracy when aligning two point clouds.
Restricted Alignment Vectors
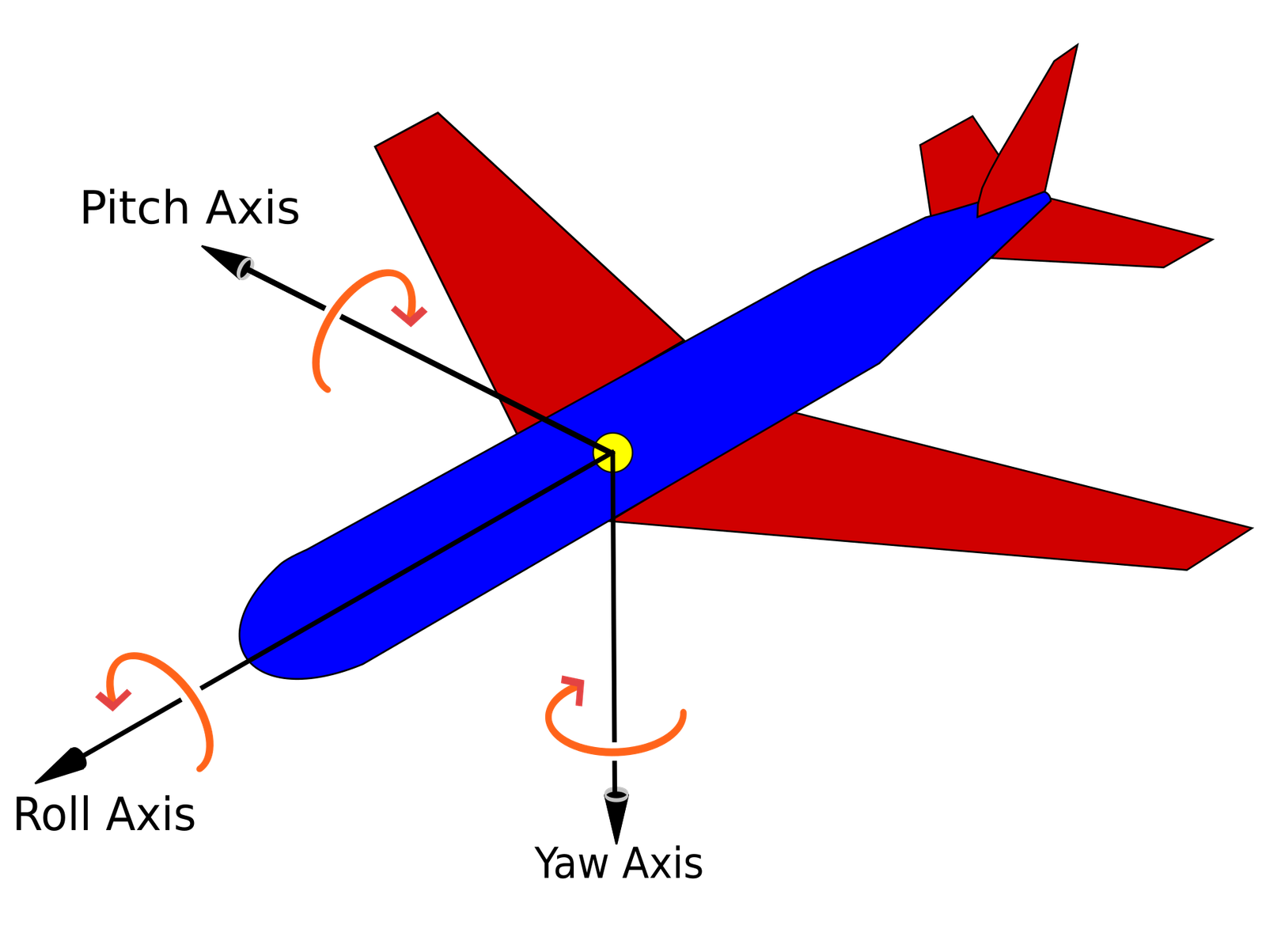


There are a few popular tools used often when aligning 3D point clouds. By default these tools will take two point clouds, and their matching points, and attempt to find the best way to align them by moving, rotating, and resizing them. With imperfect depth maps this can sometimes be a problem. Clouds may be rotated or scaled just to fit a little closer to their matching counterparts, while visually appearing closer to an M. C. Escher painting. By restricting how they can fit together we can ground the results closer to reality.
With the discovery of metric depth estimation we now know that all point clouds should be very close to each other in size. With this we can restrict the alignment algorithm’s ability to resize the point cloud. We know we are happy with the size, so if the match points don’t fit perfectly at that size, that is an inconsistency in the depthmap and will need to be addressed separately. With this restricted, we have reduced the possible transformations from 9 (3 movement, 3 rotation, 3 scale) to 6 (movement and rotation).
The other thing we identified this week was horizon alignment. Most 360 camera software rotates the image so that the horizon is in the middle of the photo, even when the camera is completely sideways. This means we can completely ignore most rotations. Any attempt the alignment tool may make to pitch or roll (Wikipedia: https://en.wikipedia.org/wiki/Aircraft_principal_axes) will most likely be incorrect. When we restrict the output to only use yaw rotations, we have effectively reduced the possible transforms from 9 to 4 (3 movement, 1 rotation).
Until we get millimeter scale GPS and elevation accuracy, the three movement vectors will likely remain. Perhaps someday the yaw rotation can be removed or minimized with a highly accurate compass. Until equipment of this caliber exists and is reasonable to use within off the shelf 360 camera equipment, this process should suffice. Applying the aforementioned steps lead to an incredible result of over 18 poses, looped, with high accuracy.
Doorway Recovery






One of the biggest challenges in 3D reconstruction is narrow areas with few features. Using RoMA v2 we’ve been able to find high confidence matches in these cases, and overcame identifying where these bridges fit within our pose tree. With distributed confidence values, we can maximize our anchors beyond the doorway. When far away, even distributed matches, with locked scale and rotations, may still be too small to properly lock our point clouds together. This issue compounds when the depthmaps through doorways become drastically less reliable, often flattening out completely. All of this may lead to a result where two adjacent rooms appear on top of one another.
To satisfy my determination to solve this problem I brainstormed a solution which subverts the current alignment tool all together. Using an image recognition model we can identify where doorways exist within an image. With that identified we can collect the keypoints that exist through that doorway. Each image, and its pointcloud, can be associated with the traits that are found on its side of the doorway, and the keypoints it seeks to match with on the other side of the door. Each trait can be mapped to it’s image’s 3D point cloud, and the camera’s position can cast a ray, or draw a line, outward to where it expects to find the points it seeks. A calculation can then be performed on the other point cloud, locking scale and rotation to yaw, to determine the best position for that point cloud to fit the expectations of both camera’s rays.
This trait and seek method proved promising in cases where the doorway is the direct threshold between two rooms. It was able to adequately align the west room despite the depthmap for each door to be incorrect and even flat. This process is slower and may not always provide the best results, so I added a check that determines when most of the keypoints exist within an opening, and only uses this process when it makes the most sense.
Edge Recovery



Sharp edges often result in incorrect depths very similar to the doorway problem. Edges of walls or counters will stretch outward in bands until they reach the estimated depth behind them, rather than cutting off sharply as things are in the real world. This deviation from ground truth causes issue when the matched points exist on these sharp edges. Because of these incorrect depths, point clouds are likely to skew and shift in relation to each other.
To solve this we can use the depthmaps to our advantage. With a simple calculation we can identify all the sharp edges of a scene where depth transitions rapidly. This generates a mask. With this mask we can identify the matching points that exist on sharp edges and are likely to be incorrect. We can then follow a similar process to handling the doorway recovery. Instead of using these points for matching the original way, we can use raycasts to identify them and align the point clouds.
Summary
Identifying a correct series of camera positions from unordered and sparse 360 imagery is a challenging feat. These cameras capture data at all angles and we use machine learning to expand this wealth of data into features and depths. The results of these modern models are marvelous. The outlier results compound and cause great deviation from achieving a ground truth set of positions. This week I have programmatically identified and removed a considerable amount of outliers from the dataset through masking. I have also reduced the calculation parameters from 9 to 5 by confirming metric depth and 2/3 of axis rotations, removing the opportunity for outlier data completely for these transforms. And when data is minimal, and deviate from ground truth, I implemented a new recovery step for doorways and sharp edges to more properly align them with the data available.
